
In our project on text-mining data from literature, we have build up a large dataset of solid-state reactions. Here, we provide our auto-generated open-source dataset of 19,744 chemical reactions retrieved from 53,538 solid-state synthesis paragraphs: text-mined dataset (updated 08/16/2019). The data are collected using an automated extraction pipeline (Figure 1) which converts unstructured scientific paragraphs describing inorganic materials synthesis into so-called “codified recipe” of synthesis. The pipeline utilizes a variety of text mining and NLP approaches to find information about target materials, starting compounds, synthesis steps and conditions in the text, and to process them into chemical equation.
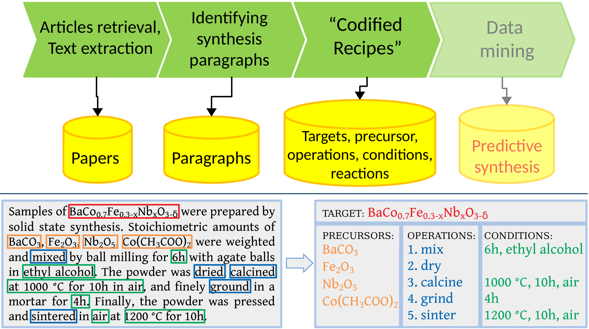 Figure 1: Pipeline of dataset creation.
Figure 1: Pipeline of dataset creation.
The generate structure of the dataset is shown in Figure 2: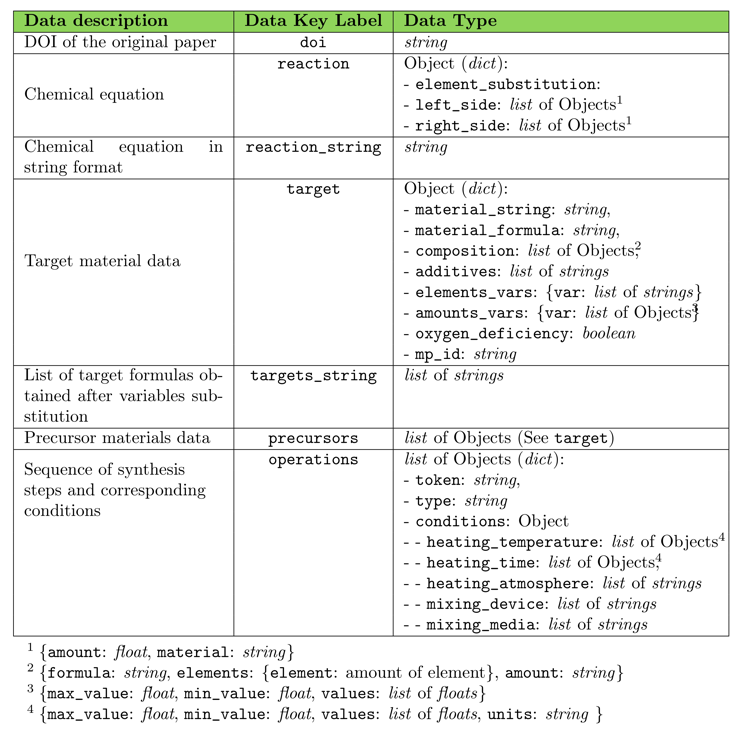
Figure 2: Structure of data in the dataset